Creating a neural network with keras
Let’s say you wanna create the following neural network:
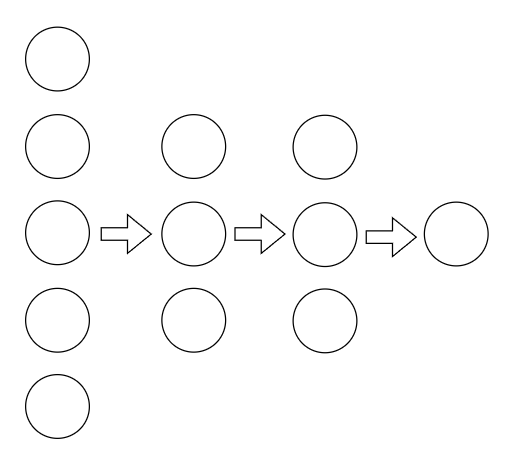
This is a dense neural network, which means that every node of a layer is connected to every other node of the adjacent layers. I have not draw these connection to avoid clutter.
Here is how you create this model in keras:
import keras
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
# add the first layer aka input layer (5 nodes, each node using the relu activation function to turn linear output to non linear output)
# note: num_features is the number of features data that this model will deal with has (number of predictors, output not included))
# each node in this layer will have num_features inputs to them
model.add(Dense(5,activation='relu', input_shape=(num_features,)))
model.add(Dense(3,activation='relu')) # add second layer (3 nodes)
model.add(Dense(3,activation='relu')) # add third layer (3 nodes)
model.add(Dense(1)) # add last layer (output layer), just 1 node
# this model should use adam instead of gradient descent to minimize error function
# use mean squared error as a measurement of error
model.compile(optimizer='adam', loss='mean_squared_error')
Here is how you train the model:
from sklearn.model_selection import train_test_split # used to randomly split training data into training/test set, can obviously do this manually instead
def normalize(df):
"""Normalize a data frame (except the last column, which is assumed to be the output). Does (data - mean) / std"""
df_copy = df.copy()
for i, column in enumerate(df_copy):
# don't do last column
if i >= df.shape[1] - 1:
break
df_copy[column] = (df_copy[column] - df_copy[column].mean()) / df_copy[column].std()
return df_copy
# normalize
df = normalize(df)
# split into train/test subsets
train_df, test_df = train_test_split(data,test_size=0.3)
# split into predictor/output columns
train_input_df = train_df[train_df.columns[train_df.columns != 'OutputColumnName']]
train_output = train_df['OutputColumnName']
test_input_df = test_df[test_df.columns[test_df.columns != 'OutputColumnName']]
test_output = test_df['OutputColumnName']
# train
model.fit(train_input_df, train_outut,epochs=50)
Here is how you test it:
actual_output = model.predict(test_input_df)
# calculate difference between actual and test (here we do mean squared error)
mse = ((actual_output.flatten() - test_output)**2).mean()